

Jeg skrev også at all informasjonen som finnes i en virksomhet kan grovsorteres i to "hauger" der den ene inneholder all strukturert informasjon, og den andre inneholder all ustrukturert informasjon. Med strukturert informasjon mener vi informasjon som består av enkeltopplysninger (som fornavn, postnummer eller telefonnummer) og som kan lagres og oppdateres enkeltvis. Resten (dokumenter, mail, bilder ++) havner i den andre haugen (som ustrukturert informasjon).
Jeg avsluttet forrige innlegg med å anbefale to separate datakataloger: En for strukturert informasjon, og en for ustrukturert informasjon. I dette innlegget skal jeg si litt mer om hvordan man kan lage en katalog over strukturert informasjon. Svaret på dette avhenger av mange ulike forhold, men det viktigste spørsmålet er om du allerede har, eller har behov for å etablere, en logisk datamodell.
Logiske datamodeller
En logisk datamodell er en datamodell (dokumentert ved hjelp av diagrammer) som skal kunne dekke all strukturert informasjon i virksomheten. En logisk datamodell ser i utgangspunktet ut som en fysisk datamodell (en datamodell som er ment å skulle implementeres fysisk i en database) men vil i motsetning til de fysiske datamodellene aldri inneholde data. Har du flere IT løsninger i bruk har du normalt en egen database med en tilhørende fysisk datamodell for hver av disse løsningene, men du vil fortsatt bare ha en logisk datamodell.
For større virksomheter kan det være aktuelt å kjøpe en
industristandard modell (det finnes flere leverandører av slike modeller) og
benytte denne som utgangspunkt for din egen logiske modell. Selv om man velger
en industrimodell, må man være forberedt på å måtte gjøre en god del
justeringer og tillegg før modellen dekker databehovet i din egen virksomhet.
Dersom det allerede finnes
en logisk datamodell, eller dersom det er besluttet at det skal etableres en
logisk datamodell for din virksomhet, vil det være naturlig å ta utgangspunkt i
denne når man skal utforme datakatalogen.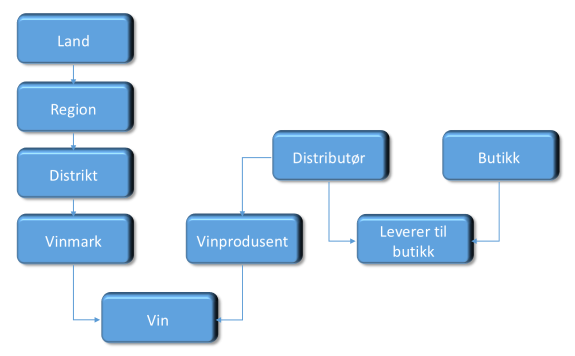
En datakatalog basert på en logisk
datamodell
En logisk datamodell er ikke hierarkisk, men det er mulig å lage en hierarkisk datakatalog basert på en logisk datamodell. Dette skjer normalt ved at man deler opp datamodellen i et håndterbart antall områder, som hver for seg består av flere dataobjekter (eller "entiteter"). Dersom datamodellen er stor (inneholder et stort antall dataobjekter), kan det bli nødvendig å ha flere enn to nivåer i datakatalogen for å gjøre den brukervennlig.
En logisk datamodell er ikke hierarkisk, men det er mulig å lage en hierarkisk datakatalog basert på en logisk datamodell. Dette skjer normalt ved at man deler opp datamodellen i et håndterbart antall områder, som hver for seg består av flere dataobjekter (eller "entiteter"). Dersom datamodellen er stor (inneholder et stort antall dataobjekter), kan det bli nødvendig å ha flere enn to nivåer i datakatalogen for å gjøre den brukervennlig.
Her er et eksempel på en enkel datakatalog med to nivåer
basert på datamodellen over. Jeg har delt opp modellen i tre områder som jeg har kalt geografidata, vindata og distribusjonsdata og dermed blir det veldig enkelt å lage en katalog av dette:
Geografidata
| |
Land
| |
Region
| |
Distrikt
| |
Vindata
| |
Vinmark
| |
Vinprodusent
| |
Vin
| |
Distribusjonsdata
| |
Distributør
| |
Leveranse
| |
Butikk
|
En logisk datamodell vil selvsagt kunne anvendes til langt mer enn som et utgangspunkt for en datakatalog og som basis for arbeidet med data governance! En logisk datamodell kan også benyttes til å beskrive standardiserte grensesnitt innenfor ulike dataområder som alle IT systemer kan forpliktes til å benytte når det skal utveksles data mellom disse systemene.
Minimumsløsningen: En enkel liste
I den andre enden av skalaen finner vi datakataloger som er etablert som en enkel liste med dataområder uten å ha en logisk data modell som utgangspunkt. Katalogen består av dataområder som er viktige for virksomheten med høy datakvalitet og god kontroll på, men som krever ulik behandling (ulike regler) og separat eierskap. Her er det mulig å starte med noen få utvalgte dataområder, for senere og utvide katalogen ved å legge til nye områder, og ved å splitte opp dataområder som viser seg å være for grove.
Kundedata
|
Ansattdata
|
Ordredata
|
Fakturadata
|
Betalingsdata
|
Produktdata
|
En veldig enkel datakatalog med ett nivå
Oppsummering
Uansett hvilken metode du har valgt for å etablere din egen datakatalog, så er det aller viktigste å passe at katalogen tas i bruk av alle som har behov for den, og at selve katalogen forvaltes på en skikkelig måte. Det finnes ingen fasit for hvordan en datakatalog skal se ut. Det finnes derfor svært mange måter å utforme en slik katalog på, og tilsvarende mange synspunkter på hvordan katalogen burde ha sett ut. Husk da på at det viktigste ikke er at alle liker katalogen! Det viktigste er at alle kjenner den og forstår den. Det at katalogen er kjent, godt dokumentert, og at den samme katalogen benyttes (og utvikles gradvis) over lang tid er de viktigste suksessfaktorene.
I neste bloggpost skal jeg si mer om hvordan du kan løse
oppgaven med å lage en katalog som dekker den ustrukturerte
informasjonen i din virksomhet! Det er som regel verre....Oppsummering
Uansett hvilken metode du har valgt for å etablere din egen datakatalog, så er det aller viktigste å passe at katalogen tas i bruk av alle som har behov for den, og at selve katalogen forvaltes på en skikkelig måte. Det finnes ingen fasit for hvordan en datakatalog skal se ut. Det finnes derfor svært mange måter å utforme en slik katalog på, og tilsvarende mange synspunkter på hvordan katalogen burde ha sett ut. Husk da på at det viktigste ikke er at alle liker katalogen! Det viktigste er at alle kjenner den og forstår den. Det at katalogen er kjent, godt dokumentert, og at den samme katalogen benyttes (og utvikles gradvis) over lang tid er de viktigste suksessfaktorene.
Petter




